AI 技術債是什麼?為什麼你的 AI 專案越做越慢、越花越多錢?
AI 導入不是終點,而是技術債的起點。Forrester 警告 AI 技術債海嘯來襲,75% 企業將面臨中高嚴重度。本文解析 AI 技術債 6 大類型、量化評估矩陣與償還優先級框架,幫助 CTO 在 AI 狂潮中守住架構底線。
AI 技術債是什麼?為什麼你的 AI 專案越做越慢、越花越多錢?
你的公司去年風風火火地導入了 AI,第一個 PoC Demo 讓全場拍手叫好。但半年過去了,你開始發現:模型回答越來越不準、每次更新要花三倍的時間、資料工程師天天在救火、新功能永遠排不上——歡迎來到 AI 技術債 的世界。
Forrester 在 2026 年初發出警告:企業正在經歷一場「AI 技術債海嘯」。根據研究,75% 的企業到 2026 年底,技術債將達到中度至高度嚴重程度,而 AI 正是最大的推手。
這篇文章將幫你釐清:AI 技術債到底是什麼、它和你熟悉的傳統技術債有什麼不同、以及最關鍵的——如何在失控之前把它管好。
什麼是 AI 技術債?和傳統技術債有什麼不同?
AI 技術債是企業在快速導入 AI 過程中,因為走捷徑、省成本或缺乏長期規劃,而在數據、模型、管線和架構層面累積的隱性負擔。 它和傳統技術債最大的差別在於:傳統技術債是「靜態」的,你不碰程式碼,它就不會變更糟;但 AI 技術債是「動態」的——即使沒人改任何東西,模型效能也會因為外部環境變化而自動衰退。
如果你已經對傳統技術債有概念,可以參考 新創技術負債管理指南 中的分類框架,以下我們來看 AI 版本有什麼不同。
傳統技術債 vs AI 技術債:一張表看懂差異
| 維度 | 傳統技術債 | AI 技術債 |
|---|---|---|
| 來源 | 程式碼品質、架構設計 | 數據品質 + 模型 + 管線 + 程式碼 |
| 可見性 | 相對容易識別(Code Smell) | 高度隱蔽(模型衰退無聲無息) |
| 增長方式 | 靜態:不碰就不惡化 | 動態:即使不碰也會自動惡化 |
| 修復路徑 | 重構程式碼 | 需要跨數據/模型/管線多維度修復 |
| 量化難度 | 中等(可用靜態分析工具) | 極高(缺乏標準化量化工具) |
| 影響範圍 | 開發速度、維護成本 | 商業決策品質、合規風險、客戶信任 |
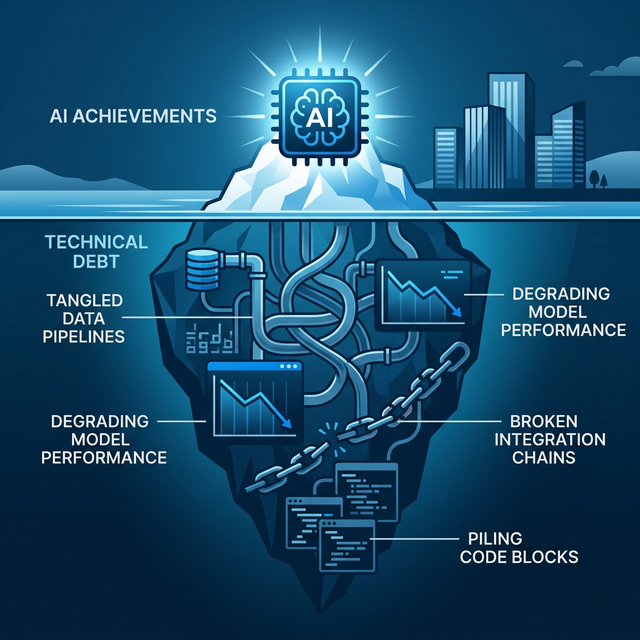
AI 技術債的 6 大類型——你中了幾個?
AI 技術債可分為 6 大類型,從數據層一路延伸到程式碼層,每一層都可能成為拖垮 AI 專案的地雷。 以下逐一拆解。
1. 數據債(Data Debt)
這是 AI 技術債中最根本、也最常被低估的類型。數據債來自於:
- 標註品質不一致:不同人用不同標準標註訓練數據,導致模型學到矛盾的模式
- 數據偏差(Bias):訓練集不夠多元,模型在特定族群或場景下表現失準
- 數據新鮮度不足:用去年的數據訓練,卻要預測今年的趨勢
2. 管線債(Pipeline Debt)
當你的數據管線從 3 條變成 30 條,恭喜你進入了「管線叢林(Pipeline Jungle)」——每一條管線都是前人為了快速交付而硬接上去的,沒有文件、沒有測試、沒有人知道改了 A 會不會炸掉 B。
3. 模型債(Model Debt)
模型債最經典的表現就是 Model Drift(模型漂移)。你的推薦模型三個月前精準得像算命仙,但現在推出來的東西客戶完全不買單——因為消費趨勢變了,而你的模型還活在三個月前的世界裡。
4. 配置債(Configuration Debt)
超參數(Hyperparameter)寫死在程式碼裡、不同環境用不同版本的模型卻沒有版本控制、訓練腳本散落在三個同事的個人電腦中——這些都是配置債。它的致命之處在於:你無法重現結果。
5. 整合債(Integration Debt)
AI 模型不是獨立運作的,它需要和 ERP、CRM、資料倉儲等系統串接。每一個串接點都是一個潛在的斷裂點。當你在評估 自建 vs 外購 AI 方案 時,整合債往往是被嚴重低估的隱藏成本。
6. AI 生成程式碼債(AI-Generated Code Debt)
2026 年最新、也最被低估的類型。當團隊大量使用 AI Coding Assistant 產出程式碼,短期內產能飆升,但 Stack Overflow 研究指出:AI 讓開發者效率 10x,同時也讓技術債產出 10x。AI 生成的程式碼缺乏架構全局觀,容易產生重複邏輯、不一致的模式和過度耦合。
| 類型 | 典型症狀 | 風險等級 | 偵測難度 |
|---|---|---|---|
| 數據債 | 模型表現不穩定、偏差投訴 | 🔴 高 | 🔴 高 |
| 管線債 | 更新一個管線、炸掉三個 | 🔴 高 | 🟡 中 |
| 模型債 | 準確率逐月下降 | 🔴 高 | 🟡 中 |
| 配置債 | 無法重現訓練結果 | 🟡 中 | 🟢 低 |
| 整合債 | 系統串接頻繁斷裂 | 🟡 中 | 🟢 低 |
| AI 程式碼債 | Code Review 發現大量重複邏輯 | 🟡 中 | 🟡 中 |
AI 技術債的真實成本有多驚人?
根據 IBM 研究,一家年營收 200 億美元的企業若將 20% IT 預算投入 AI,技術債每年可額外增加超過 1.2 億美元的隱藏實施成本。 Gartner 更估計,全球未被管理的 AI 技術債到 2026 年將累積達 2 兆美元。
這些數字之所以驚人,是因為大多數企業只看到了 AI 導入的「顯性成本」(模型訓練、API 費用、工程師薪水),卻忽略了三大隱性成本(更完整的 5 大隱藏成本與佔比試算可參考 AI ROI 4 層評估框架):
- 維運成本膨脹:模型監控、重新訓練、數據管線維護的持續人力投入
- 機會成本:工程團隊 70% 的時間在修修補補,沒有餘力開發新功能
- 決策品質下降:衰退的模型產出錯誤的洞察,導致商業決策失準
想更深入了解企業 AI 轉型中的成本陷阱,推薦延伸閱讀 2026 企業 AI 轉型的實戰與避坑指南。
為什麼 AI 技術債比傳統技術債更難發現?
傳統技術債有成熟的偵測工具——靜態分析、Code Smell 檢查、測試覆蓋率。但 AI 技術債的偵測困難在於:
- 衰退是漸進的:模型不會突然壞掉,它是慢慢變差,差到有人投訴才被發現
- 因果關係模糊:模型效能下降,是因為數據問題?模型問題?還是上游系統改了什麼?
- 缺乏標準化指標:業界至今沒有像「程式碼覆蓋率」一樣通用的 AI 健康度指標
如何量化你的 AI 技術債?評估矩陣實戰
量化 AI 技術債的核心思路是:將技術風險轉化為商業影響金額。 以下提供一個實用的評估矩陣。
| 評估維度 | 健康 (0-2分) | 警戒 (3-5分) | 危險 (6-8分) | 緊急 (9-10分) |
|---|---|---|---|---|
| 模型效能趨勢 | 穩定或上升 | 輕微下降但可接受 | 明顯下降,客戶投訴 | 嚴重失準,影響營收 |
| 數據管線穩定度 | 自動化、有監控 | 偶爾需手動介入 | 頻繁手動介入 | 每週都在救火 |
| 模型可重現性 | 100% 可重現 | 大部分可重現 | 需要特定人員才能跑 | 完全無法重現 |
| 文件完整度 | 完整且即時 | 大部分有文件 | 關鍵流程無文件 | 什麼文件? |
| 團隊依賴度 | 任何人都能維護 | 需特定團隊 | 需特定個人 | 那個人已經離職了 |
三步驟自評法
步驟一:盤點——列出所有正在運行的 AI 模型和數據管線,標註每個的負責人、最後更新時間、監控狀態。
步驟二:評分——用上述矩陣為每個系統打分,總分超過 30 分的系統應立即進入修復排程。
步驟三:定價——計算每個技術債項目的商業影響。例如:「推薦模型準確率下降 5%,每月減少 XX 萬營收」。這個數字就是你跟老闆爭取資源的武器。
AI 技術債怎麼還?償還優先級框架
償還 AI 技術債不是一次性的大掃除,而是分層、分階段的持續治理。 以下是經過實戰驗證的三級優先框架。
第一優先:止血——模型監控與漂移偵測
在還任何債之前,你必須先「看得到」問題在哪。
- 部署模型效能監控(精準度、延遲、吞吐量的即時 Dashboard)
- 建立 Data Drift 與 Concept Drift 的自動偵測與告警機制
- 設定效能衰退閾值:當模型指標低於基準線 X% 時自動觸發重新訓練流程
第二優先:固本——數據治理與管線重構
確認問題在哪之後,從源頭治理。
- 建立統一的數據品質標準與驗證流程
- 拆解「管線叢林」,建立模組化、可測試的 ETL 架構
- 導入數據版本控制(如 DVC),確保每次訓練的數據可追溯
當企業進一步擴展到多 Agent 系統時,管線的複雜度會指數級增長——詳見為什麼單一 AI Agent 不夠用?2026 多代理協作架構的企業實戰指南中的系統化治理框架。
第三優先:升級——MLOps 與自動化
把手動流程系統化,建立長期免疫力。
- 導入 MLOps 平台,實現模型訓練、測試、部署的 CI/CD
- 建立模型註冊中心(Model Registry),管理所有模型的版本與生命週期
- 自動化特徵工程和模型重訓練管線
關於 MLOps 在企業 AI 規模化中的實踐,可延伸參考 AI Agent 規模化部署的治理框架。
| 階段 | 投入時間 | 預期效果 | 關鍵產出 |
|---|---|---|---|
| 止血(監控) | 2-4 週 | 問題可視化,止損 | 監控 Dashboard + 告警規則 |
| 固本(數據治理) | 1-3 個月 | 數據品質提升,管線穩定 | 數據品質 SLA + 模組化管線 |
| 升級(MLOps) | 3-6 個月 | 持續交付能力,團隊效率 | CI/CD + Model Registry |
企業導入 AI 時如何「預防」技術債?
最好的技術債管理是預防。 以下是從 Day 1 就該做對的 5 件事。
從 Day 1 就該做對的 5 件事
-
先定義「退場標準」再開始:每個 AI 專案啟動時,就要定義「什麼情況下我們會停止這個專案」。這能避免殭屍專案無限期消耗資源。
-
選擇 Buy 優先於 Build:除非 AI 是你的核心產品,否則優先串接成熟的 API 服務,而非自建模型。這能從根本上減少模型債、管線債和配置債。
-
強制 AI 程式碼 Review 流程:把 AI 生成的程式碼當作 Junior 開發者的產出,每一行都要經過 Senior 的 Review。禁止未經審查的 AI 程式碼直接進入主分支。
-
建立模型健康 SLA:像你監控 API 可用性一樣監控模型健康。定義精準度、延遲、覆蓋率的最低標準,低於標準就觸發修復流程。
-
預留 20% 維運預算:AI 不是「部署上線就結束」的專案。在初始預算中就預留至少 20% 給後續的監控、重訓練和管線維護。
顧問觀點: 我見過太多企業把 100% 的 AI 預算花在「建設期」,上線後才發現維運費用完全沒有著落。AI 系統就像一輛車,買車只是第一筆錢,油錢、保養、保險才是長期支出。如果你連油錢都沒準備,那這輛車只會變成一個昂貴的裝飾品。
常見問題 FAQ
AI 技術債和一般技術債最大的差別是什麼?
傳統技術債主要來自程式碼品質問題,修復路徑明確。AI 技術債則涉及數據品質、模型衰退、管線複雜度等多維度問題,且會隨時間「自動增長」——即使沒有人動程式碼,模型效能也會因為真實世界數據分布改變而下降。這種「動態衰退」特性是 AI 技術債最獨特也最危險的地方。
中小企業導入 AI 也會有技術債問題嗎?
會,而且可能更嚴重。中小企業通常缺乏專職的 MLOps 團隊,AI 專案往往由少數工程師兼任維護,一旦關鍵人員離職,整個 AI 系統就成了沒人敢動的黑盒子。建議中小企業優先採用 API 串接而非自建模型,從源頭降低技術債風險。
AI 技術債要怎麼跟老闆解釋?
用財務語言溝通最有效。告訴老闆:「我們的 AI 模型準確率每下降 1%,客服成本就增加 X 萬元」或「不處理數據管線問題,每次模型更新要多花 3 倍工時」。把技術債轉化為具體的金額和時間成本,決策者才聽得懂。建議搭配上方的評估矩陣,把數字攤在桌上。
模型衰退(Model Drift)多久會發生?
取決於應用場景。面對快速變動市場(如電商推薦、金融風控)的模型,可能 2-4 週就出現明顯衰退。相對穩定的場景(如文件分類、內部知識問答)可能撐 3-6 個月。關鍵不是猜測衰退何時發生,而是建立持續監控機制,用數據即時偵測而非靠感覺判斷。
用 AI 寫程式碼會產生更多技術債嗎?
會,這是 2026 年最被低估的風險之一。Stack Overflow 研究指出,AI 讓開發者產出效率提升 10 倍,但同時也 10 倍速地產出技術債。AI 生成的程式碼缺乏架構全局觀,容易造成重複邏輯、不一致的錯誤處理和過度耦合。解方是:把 AI 當 Junior 開發者,所有產出都必須經過嚴格的 Code Review,並且禁止未審查的 AI 程式碼進入生產環境。
結語:在 AI 狂潮中守住架構底線
AI 技術債不是可以「以後再說」的問題。它是一顆已經在倒數的定時炸彈——你不處理它,它就會處理你的商業成果。
好消息是,只要有正確的認知和系統化的管理框架,AI 技術債完全可以被控制在合理範圍內。從今天開始:盤點你的 AI 資產、量化技術債的商業影響、按優先級逐步償還,並在每個新專案中從 Day 1 就植入預防機制。
如果你的企業正在導入 AI,或者已經感受到 AI 專案「越做越慢」的痛苦,歡迎預約免費的 AI 架構健檢諮詢,讓我們一起找出你的技術債熱點,制定量身定做的償還計畫。
分享這篇文章
